贫血模型
概念
只包含数据,不包含业务逻辑的类,就叫作 贫血模型(Anemic Domain Model) 。
结构
在前后端分离的项目中,服务端基于 MVC 三层架构,分为 :
Repository 层: 负责数据访问。返回Entity结构数据。Service 层:负责业务逻辑。调用Repository获取到Entity数据,转为Bo, 提供给Controller层。Controller 层:负责暴露接口。从Service拿到Bo后,转为Vo返回给前端。
例:
////////// Controller+VO(View Object) //////////
public class UserController {
private UserService userService; //通过构造函数或者IOC框架注入
public UserVo getUserById(Long userId) {
UserBo userBo = userService.getUserById(userId);
UserVo userVo = [...convert userBo to userVo...];
return userVo;
}
}
public class UserVo {//省略其他属性、get/set/construct方法
private Long id;
private String name;
private String cellphone;
}
////////// Service+BO(Business Object) //////////
public class UserService {
private UserRepository userRepository; //通过构造函数或者IOC框架注入
public UserBo getUserById(Long userId) {
UserEntity userEntity = userRepository.getUserById(userId);
UserBo userBo = [...convert userEntity to userBo...];
return userBo;
}
}
public class UserBo {//省略其他属性、get/set/construct方法
private Long id;
private String name;
private String cellphone;
}
////////// Repository+Entity //////////
public class UserRepository {
public UserEntity getUserById(Long userId) { //... }
}
public class UserEntity {//省略其他属性、get/set/construct方法
private Long id;
private String name;
private String cellphone;
}
其中 Bo 是纯粹的数据结构,不包含任何业务逻辑。业务逻辑集中在 Service 中。我们通过 Service 来操作 Bo。
同理,Entity、Vo 都是基于贫血模型设计的。这种贫血模型将数据与操作分离,破坏了面向对象的封装特性,是一种典型的面向过程的编程风格。
基于DDD的充血模型
概念
充血模型(Rich Domain Model)中,数据和对应的业务逻辑被封装到同一个类中。因此,这种充血模型满足面向对象的封装特性,是典型的 面向对象编程 风格。跟基于贫血模型的传统开发模式的区别主要在 Service 层。
结构
在基于充血模型的 DDD开发模式 中,Service 层包含 Service 类 和 Domain 类 两部分。
Domain 就相当于贫血模型中的 BO。不过,Domain 与 BO 的区别在于它是基于充血模型开发的,既包含数据,也包含业务逻辑。
而 Service 类变得非常单薄。
总结一下的话就是,基于贫血模型的传统的开发模式,重 Service 轻 BO;基于充血模型的 DDD开发模式,**轻 Service 重 Domain **。
贫血模型泛滥的原因
- 业务简单。 大部分情况下,我们开发的系统业务可能都比较简单,简单到就是基于 SQL 的 CRUD 操作,所以,我们根本不需要动脑子精心设计充血模型,贫血模型就足以应付这种简单业务的开发工作。
除此之外,因为业务比较简单,即便我们使用充血模型,那模型本身包含的业务逻辑也并不会很多,设计出来的领域模型也会比较单薄,跟贫血模型差不多,没有太大意义。 - 充血模型更复杂。 充血模型是一种面向对象的编程风格。我们从一开始就要设计好针对数据要暴露哪些操作,定义哪些业务逻辑。
而不是像贫血模型那样,我们只需要定义数据,之后有什么功能开发需求,我们就在 Service 层定义什么操作,不需要事先做太多设计。 - 思维已固化,转型有成本。 转向用充血模型、领域驱动设计,那势必有一定的学习成本、转型成本。很多人在没有遇到开发痛点的情况下,是不愿意做这件事情的。
开发流程
-
SQL 驱动(SQL-Driven) 的贫血模型开发模式,让代码越来越混乱,最终导致无法维护。
我们平时的开发,根据接口需要的数据对应到数据库中,需要哪张表或者哪几张表,然后思考如何编写 SQL 语句来获取数据。
之后就是定义Entity、BO、VO,然后模板式地往对应的Repository、Service、Controller类中添加代码。
业务逻辑包裹在一个大的 SQL 语句中,而Service层可以做的事情很少。
SQL 都是针对特定的业务功能编写的,复用性差。
当我要开发另一个业务功能的时候,只能重新写个满足新需求的 SQL 语句,这就可能导致各种长得差不多、区别很小的 SQL 语句满天飞。 -
基于 充血模型 的 DDD 开发模式更加适合这种复杂系统的开发。
我们需要事先理清楚所有的业务,定义领域模型所包含的属性和方法。领域模型相当于可复用的业务中间层。新功能需求的开发,都基于之前定义好的这些领域模型来完成。
越复杂的系统,对代码的复用性、易维护性要求就越高,我们就越应该花更多的时间和精力在前期设计上。而基于充血模型的 DDD 开发模式,正好需要我们前期做大量的业务调研、领域模型设计。
例:基于充血模型的DDD开发虚拟钱包系统
需求
很多具有支付、购买功能的应用(比如淘宝、滴滴出行、极客时间等)都支持钱包的功能。
应用为每个用户开设一个系统内的虚拟钱包账户,支持用户充值、提现、支付、冻结、透支、转赠、查询账户余额、查询交易流水等操作。
- 充值
- 体现
- 支付
- 查询余额
- 查询流水
钱包功能对应虚拟钱包系统的操作:

数据结构设计
- 交易流水有的两种数据结构设计方式
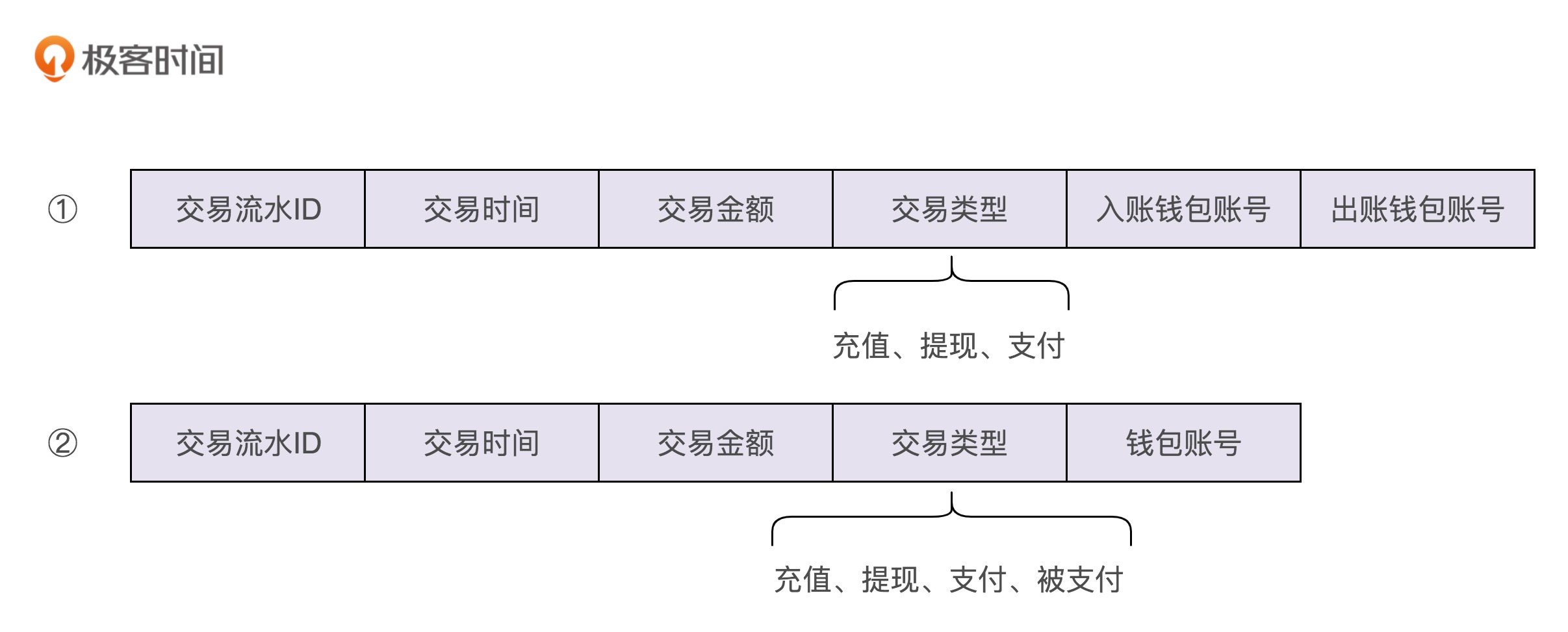
方式二在执行 支付 操作时,需要记录两笔数据。方式一在执行 充值、提现 操作时,会有一个字段的空间被浪费。
支付 实际上就是一个转账的操作,在一个账户上加上一定的金额,在另一个账户上减去相应的金额。
我们需要保证加金额和减金额这两个操作,要么都成功,要么都失败。
如果一个成功,一个失败,就会导致数据的不一致,一个账户明明减掉了钱,另一个账户却没有收到钱。
保证数据一致性的方法有很多,比如依赖数据库事务的原子性。
但是如果做了分库分表,为了保证数据的强一致性,利用分布式事务的开源框架,逻辑一般都比较复杂、本身的性能也不高,会影响业务的执行时间。
权衡利弊,我们选择方式一这种稍微有些冗余的数据格式设计思路。
- 虚拟钱包系统不应该感知具体的业务交易类型
虚拟钱包支持的操作,仅仅是余额的加加减减操作,不涉及复杂业务概念,职责单一、功能通用。
如果耦合太多业务概念到里面,势必影响系统的通用性,而且还会导致系统越做越复杂。
因此,我们不希望将充值、支付、提现这样的业务概念添加到虚拟钱包系统中。
我们不应该在 虚拟钱包系统交易流水 中记录交易类型,而应该将交易类型记录在 钱包交易流水 中:

我们通过查询上层 钱包系统 的交易流水信息,去满足用户查询交易流水的功能需求,而 虚拟钱包 中的交易流水就只是用来解决数据一致性问题。实际上,它的作用还有很多,比如用来对账等。
代码设计
public class VirtualWalletController {
// 通过构造函数或者IOC框架注入
private VirtualWalletService virtualWalletService;
public BigDecimal getBalance(Long walletId) { ... } //查询余额
public void debit(Long walletId, BigDecimal amount) { ... } //出账
public void credit(Long walletId, BigDecimal amount) { ... } //入账
public void transfer(Long fromWalletId, Long toWalletId, BigDecimal amount) { ...} //转账
}
public class VirtualWallet { // Domain领域模型(充血模型)
private Long id;
private Long createTime = System.currentTimeMillis();;
private BigDecimal balance = BigDecimal.ZERO;
public VirtualWallet(Long preAllocatedId) {
this.id = preAllocatedId;
}
public BigDecimal balance() {
return this.balance;
}
public void debit(BigDecimal amount) {
if (this.balance.compareTo(amount) < 0) {
throw new InsufficientBalanceException(...);
}
this.balance.subtract(amount);
}
public void credit(BigDecimal amount) {
if (amount.compareTo(BigDecimal.ZERO) < 0) {
throw new InvalidAmountException(...);
}
this.balance.add(amount);
}
}
public class VirtualWalletService {
// 通过构造函数或者IOC框架注入
private VirtualWalletRepository walletRepo;
private VirtualWalletTransactionRepository transactionRepo;
public VirtualWallet getVirtualWallet(Long walletId) {
VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);
VirtualWallet wallet = convert(walletEntity);
return wallet;
}
public BigDecimal getBalance(Long walletId) {
return walletRepo.getBalance(walletId);
}
public void debit(Long walletId, BigDecimal amount) {
VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);
VirtualWallet wallet = convert(walletEntity);
wallet.debit(amount);
walletRepo.updateBalance(walletId, wallet.balance());
}
public void credit(Long walletId, BigDecimal amount) {
VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);
VirtualWallet wallet = convert(walletEntity);
wallet.credit(amount);
walletRepo.updateBalance(walletId, wallet.balance());
}
public void transfer(Long fromWalletId, Long toWalletId, BigDecimal amount) {
VirtualWalletTransactionEntity transactionEntity = new VirtualWalletTransactionEntity();
transactionEntity.setAmount(amount);
transactionEntity.setCreateTime(System.currentTimeMillis());
transactionEntity.setFromWalletId(fromWalletId);
transactionEntity.setToWalletId(toWalletId);
transactionEntity.setStatus(Status.TO_BE_EXECUTED);
Long transactionId = transactionRepo.saveTransaction(transactionEntity);
try {
debit(fromWalletId, amount);
credit(toWalletId, amount);
} catch (InsufficientBalanceException e) {
transactionRepo.updateStatus(transactionId, Status.CLOSED);
...rethrow exception e...
} catch (Exception e) {
transactionRepo.updateStatus(transactionId, Status.FAILED);
...rethrow exception e...
}
transactionRepo.updateStatus(transactionId, Status.EXECUTED);
}
}
其中 Service 类承担的职责:
-
Service类负责与Repository交流。 调用Respository类的方法,获取数据库中的数据,转化成领域模型VirtualWallet,然后由领域模型VirtualWallet来完成业务逻辑,
最后调用Repository类的方法,将数据存回数据库。让
VirtualWalletService类与Repository打交道,而不是让领域模型VirtualWallet与Repository打交道,
那是因为我们想保持领域模型的独立性,不与任何其他层的代码(Repository层的代码)或开发框架(比如Spring、MyBatis)耦合在一起,
将流程性的代码逻辑(比如从 DB 中取数据、映射数据)与领域模型的业务逻辑解耦,让领域模型更加可复用。 -
Service类负责跨领域模型的业务聚合功能。VirtualWalletService类中的transfer()转账函数会涉及两个钱包的操作,
因此这部分业务逻辑无法放到VirtualWallet类中,所以,我们暂且把转账业务放到VirtualWalletService类中了。
当然,虽然功能演进,使得转账业务变得复杂起来之后,我们也可以将转账业务抽取出来,设计成一个独立的领域模型。 -
Service类负责一些非功能性及与三方系统交互的工作。 比如幂等、事务、发邮件、发消息、记录日志、调用其他系统的 RPC 接口等,都可以放到Service类中。
Controller 层和 Repository 层没有必要进行充血领域建模
-
Controller层主要负责接口的暴露,Repository层主要负责与数据库打交道,这两层包含的业务逻辑并不多,前面我们也提到了,如果业务逻辑比较简单,就没必要做充血建模,
即便设计成充血模型,类也非常单薄,看起来也很奇怪。只要控制好面向过程编程风格的副作用,照样可以开发出优秀的软件。 -
Repository的Entity来说,即便它被设计成贫血模型,违反面向对象编程的封装特性,有被任意代码修改数据的风险,
但Entity的生命周期是有限的。
一般来讲,我们把它传递到Service层之后,就会转化成BO或者Domain来继续后面的业务逻辑。Entity的生命周期到此就结束了,所以也并不会被到处任意修改。 -
Controller层的VO。实际上VO是一种 DTO(Data Transfer Object,数据传输对象)。
它主要是作为接口的数据传输承载体,将数据发送给其他系统。
从功能上来讲,它理应不包含业务逻辑、只包含数据。所以,我们将它设计成贫血模型也是比较合理的。